When practicing DDD, tactical patterns could be utilized in implementation in the solution space. (problem space / solution space). These patterns could be used in our service/component definition.
In addition to the basic patterns, there are a few building blocks that could also aid us.
| Name | Formula |
|---|---|
| Application Service | command -> unit |
| Application Service | command -> event* |
| Enricher | event -> event |
| Policy | event -> event |
| Receptor | event -> command |
Examples as follows.
Commands and events are central in all examples. In OO some registry for handlers could be handy (or pattern matching available). Commands have one target, events are broadcasted. In the EventProcessor we use locks as mentioned in the variants above.
8 lines of code (video)
To broadcast events. Some consumer that don’t need the lock, might want to another way of broadcasting or handling IO than Task.WhenAll.
When dispatching commands to application services, a util could come in handy to support some of the variants above. This could be used in Application services for your use cases or in simple scenarios directly in the dispatcher.
If state is based on events, test could be like:
See event driven verification.
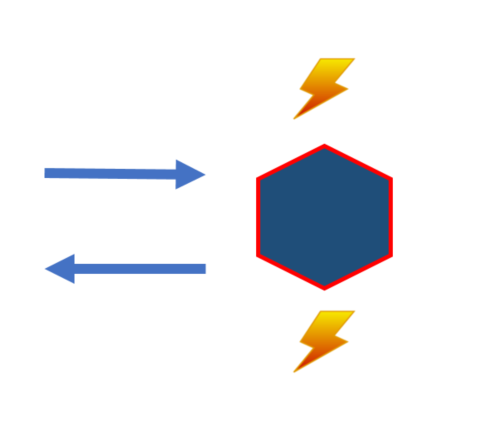
Our scenario of focus is a service that owns state, with possible constraints implemented to protect its state from illegal invariants.
Consumers that only own projection(s) of these events, does not have the same complexity.
In the examples above When is handled by the dispatcher, Then (event returned by the aggregate) is handled by the EventProcessor (in many cases).
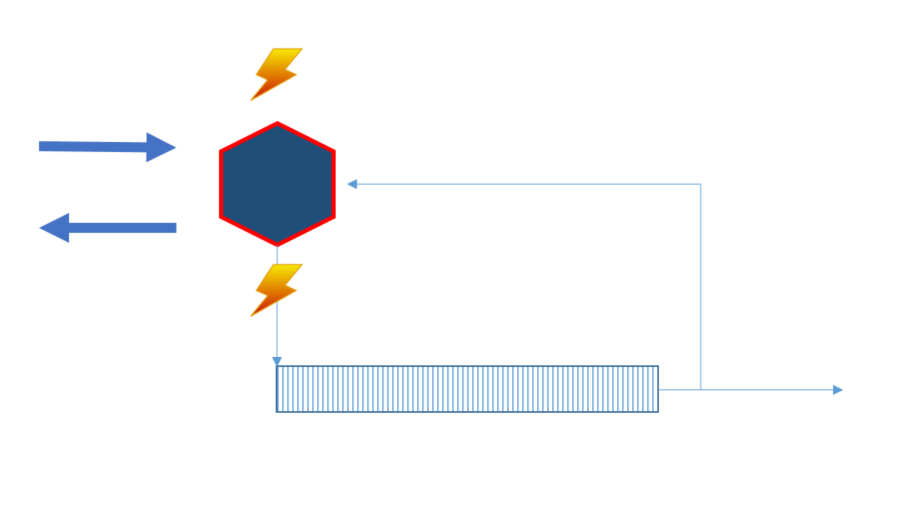
Our goal is to write events in “one” transaction (to all consumers), and use aggregates to scope and aid concurrency.
We use locks in the example to illustrate how when could be used through an api. When the service is both a producer and a consumer (changes state protected by constraints - handles both when and then) it needs to share the same lock reference. This way an aggregate only handles one command at a time with the latest state.
The producer is also a consumer due to that we want to write our events (in this case to the log) in one transaction, so all consumers (including the producer) receives the events. The producer receives the events at the “same time” as consumers. In our example locks are used to aid both concurrency and options for the api to respond.
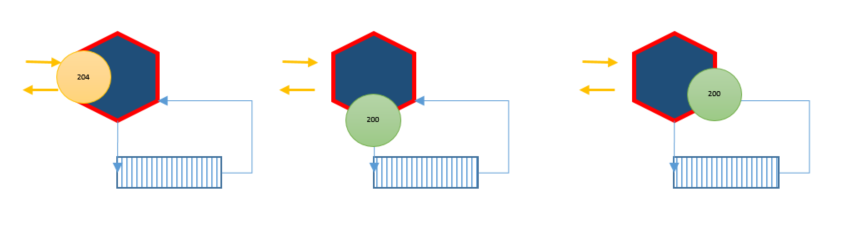
This gives us quite a lot of implementation options.
When creating a service/component it could aid tests to ease the use of setup to use given, when, then apis.
The publisher could either write/publish events to a log or/and an eventstore stream. Consumers could then get events trough the log, eventstore or service api.
When the consumers gets events through the log, integration is done via the log and no other coupling is introduced (besides infrastructure and schema).
The producer could also expose its events through ex Atom feed, the consumer would then pull changes from the producer. This would introduce coupling between the services, but ease implementation code wise.
The consumer could also get published events from the event stream from its store, tying integration to the “database”.
Databases like Eventstore or CosmosDB offers subscriptions for changes. These could also be used to create a single publisher.
It’s still the consumers responsibility to keep track of what position it should read from. EventStore has this notion (catchup subscription) In CosmosDB the partition key range could be used.
Actors is used for concurrency guarantee (and scaling), incoming commands are queued (inbox) per actor instance, allowing one command to change the instance state at a time. Using actors, you still face the same challenges in writing (and publishing) state/events to its persistence (and log) in a transactional way. Some of the challenges could be solved by the actor framework.
Service fabric offers an actor model out of the box and does also support Orleans and other Actor frameworks.
Service fabric let you work with an instance queue and its state in a single transaction (with replication support) and load balancer with partition support.
So even if you don’t use actors service fabric has a lot of features that suite our scenarios. But if you don’t use its persistence model, some of the challenges in this article still apply.
When creating components in aspnetcoremvc 2.0 that either subscribes to a log, stream subscription or polls a feed IHostedService provides hosting an http api an creating background work with the same lifetime as the api host.
EventGrid is a event delivery and routing service. Using EventGrid introduces a new service that becomes the integration point. EventGrid pushes Events to functions, logic apps or to web hooks. The grid is Topic based and offers at-least-once delivery but retry and persistence time is 24h.
An app could publish event to eventgrid through http, or built-in in hooks from event publishers like from Event hubs could be used.
This gives us a lot of options, events could be written to a log, but routed to web hooks, for easier apis for consumers.
Two services could integrate only through eventgrid, a possibility to even only use eventgrid to get one transaction is possible where the producing service pushes events to the grid and also is a web hook consumer (that would release the lock).
But Event grid is different, it dispatches it’s event in parallel, to use auto scaling of the target service(s). This way we loose ordering guarantees. Publishing state events through event grid might not be a good option, until we could configure the level of parallelism and guarantee ordering. The Event grid target other use cases, more suitable for notification events.
Many of these scenarios is about a service/component that is both a producer and a consumer, that want a single transaction before events are in some way persisted. Locks enables the api to know when the events are persisted in a log stream or when it’s also retrieved and persisted in the component eventstore.
If you have another scenario where you poll or in other way subscribe to events that’s already persisted or just a service with projections, you don’t need to share a locks reference in the same process. Then serverless independent functions for publisher and consumers could be used with ease. If a function is for an interaction (command) you still have to choose a concurrency option.
Creating a serverless function per aggregate has challenges. Concurrency, store and publishing of events.
Some persistence infrastructure and brokers are capable to share transaction scope to handle/hide the 2PC.
A consumer could have background task polling the producer in a given time interval. The IHostedService in aspnetcore 2.0 could be useful for such an implementation. Offset needs to be persisted by the consumer (and given by the producer), Service fabric’s could be used to pull events to the local queue, the pop the the queue and due state changes in a shared transaction.
In a serverless scenario the task of polling could be it’s own function/process.
In some cases polling and single publisher have a lot in common. But the polling in this case is tied to the producer. One single task polls for changes and publishes them on a log or broker.
Some infrastructure might give you a subscription that could ease the implementation of the single publisher. Both eventstore and CosmosDB has features the could be used.
The IHostedService in aspnetcore 2.0 could be useful for such an implementation.
In a serverless scenario the single publisher could be it’s own function/process.
The consumer uses the log infrastructure apis to subscribe/poll the log. Offset tracking etc. is usually handled by the log client apis. The subscription could run as a separate task using aspnetcore 2.0’s IHostedService for ex.
In a serverless scenarios, depending on your concurrency choices, the subscription could also be is own function/process.
Azure Event grid might be introduced, so the log subscription is handled by the event grid, that then pushes events to the consumer using a web hook for ex. Switching the consumer from pull to push. (But due another focus/feature set event grid is not being suitable for publishing state transfer events).
Is this scenario, it’s still a log subscription, but with other retention or compaction settings. So separating initializing and catch up are implementation details. All log subscription implementations is applicable.
Kafka offers both log compaction and configurable retention. Giving the consumer the same api for “restore”/replay and subscribing.
Event hubs, has two api’s due to it solve this problem with Event hubs capture, storing batches of events in avro format in configurable storage options.